HashMap底层原理
大约 4 分钟
阅读提示
这页建议按“数据结构 -> put/get 流程 -> 扩容与树化 -> 线程安全”顺序复习。
面试回答时先给结论,再补阈值和条件(如 0.75、8、64)。
1、HashMap 的底层数据结构是什么?
回答提示:
- JDK 1.7:数组 + 链表。
- JDK 1.8:数组 + 链表 + 红黑树。
- 当桶内链表过长且容量达到条件时,链表会树化,提高查询效率。
参考回答:
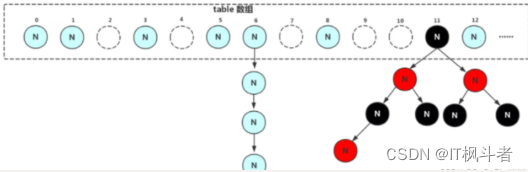
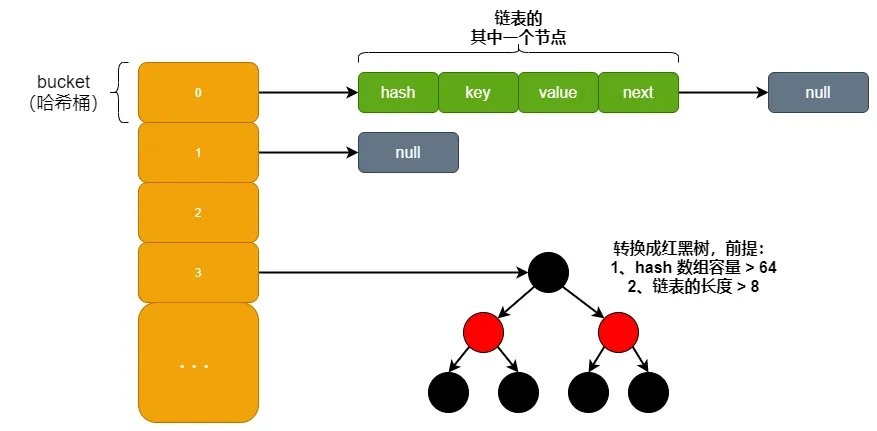
- HashMap 的底层是哈希桶数组,桶里存放
Node<K, V>。 - 发生哈希冲突时,会形成链表;在 JDK 1.8 中,当链表长度达到阈值后会转成红黑树。
2、HashMap 的默认初始化参数有哪些?
回答提示:
- 默认初始容量:
16。 - 默认负载因子:
0.75。 - 扩容阈值:
capacity * loadFactor。
参考回答:
- 默认情况下,HashMap 在第一次
put时初始化数组容量为 16。 - 当元素个数超过阈值(容量 * 负载因子)时,触发扩容,容量通常翻倍。
3、HashMap 的 put 流程是怎样的?
回答提示:
- 计算 key 的 hash。
- 定位桶下标(位运算)。
- 桶为空直接插入。
- 桶不为空则比较 key:相同覆盖,不同挂链表/树。
- 判断是否需要树化或扩容。
参考回答:
put核心逻辑就是“算桶位 + 冲突处理 + 阈值判断”。- 冲突时先比较
hash和equals,相同 key 走覆盖;不同 key 追加到链表尾或红黑树。
4、HashMap 的 get 流程是怎样的?
回答提示:
- 计算 key 的 hash 并定位桶。
- 先比较头节点。
- 若是链表则遍历匹配。
- 若是红黑树则按树查找。
参考回答:
get的时间复杂度在理想情况下接近 O(1),冲突严重时会退化。- JDK 1.8 通过树化降低极端冲突下链表查询的退化风险。
5、哈希冲突怎么处理?
回答提示:
- HashMap 主要采用拉链法(链地址法)。
- 同一个桶位的不同 key 通过链表或红黑树组织。
参考回答:
- 哈希冲突不可避免,关键是“冲突后怎么组织”。
- HashMap 采用“数组 + 链/树”结构,把冲突元素放在同一个桶中并继续检索。
6、链表什么时候转红黑树?红黑树什么时候退化回链表?
回答提示:
- 树化条件:链表长度 >=
8且数组长度 >=64。 - 退化条件:树节点数 <=
6时,可能退化为链表。
参考回答:
- 只有在“链表过长且表容量足够大”时才树化,避免小表频繁树化带来的维护成本。
- 节点减少到一定程度时会退化,减少树结构开销。
7、为什么要引入红黑树?
回答提示:
- 解决极端冲突下链表查询退化到 O(n) 的问题。
- 红黑树可将查找复杂度优化到 O(log n)。
参考回答:
- 红黑树是为了优化最坏情况性能,不是为了替代链表。
- 在冲突不严重时,链表简单且维护成本低;冲突严重时,树结构更稳。
8、HashMap 在什么情况下扩容?
回答提示:
- 元素个数 > 阈值(
capacity * loadFactor)时扩容。 - 扩容通常翻倍,并触发重新分布(rehash)。
参考回答:
- 扩容会带来一次性开销,因此在已知数据量场景建议设置合理初始容量,减少频繁扩容。
9、JDK 1.7 与 1.8 在扩容迁移上的差异
回答提示:
- 1.7 迁移时头插法,链表顺序可能反转。
- 1.8 迁移更稳定,降低并发条件下异常风险。
参考回答:
- 常见面试追问是 1.7 扩容并发下的链表成环问题。
- 1.8 在结构和迁移策略上做了改进,但 HashMap 依然不是线程安全容器。
10、HashMap 为什么线程不安全?
回答提示:
- 多线程下可能出现覆盖、丢失、结构异常。
- 并发扩容和写入存在竞态条件。
参考回答:
- HashMap 适用于单线程或外部同步场景。
- 并发读写建议使用
ConcurrentHashMap。
11、面试如何表达得更工程化?
可直接复述模板:
- 我一般先确认访问模式(读多写少还是高并发写入),再决定用 HashMap 还是 ConcurrentHashMap。
- 如果数据量可预估,我会提前设置初始容量,减少扩容抖动。
- 如果 key 分布不均,我会重点关注冲突桶和热点 key,避免局部性能退化。